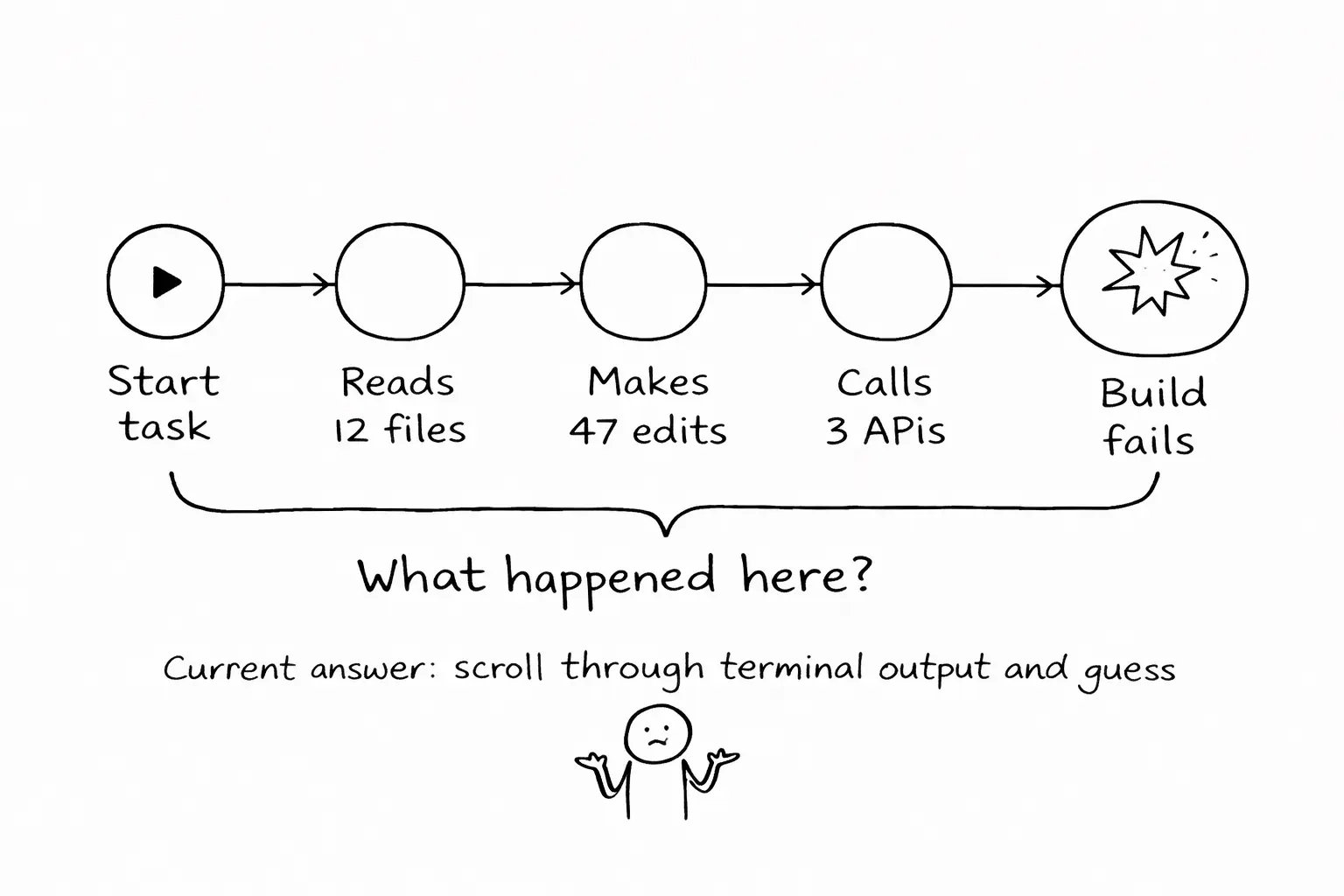
Last month, an agent I was running modified 47 files across 12 directories, made three API calls, ran the test suite twice, and the build failed. I spent twenty minutes scrolling through terminal output trying to find what went wrong.
I never found it. I started over.
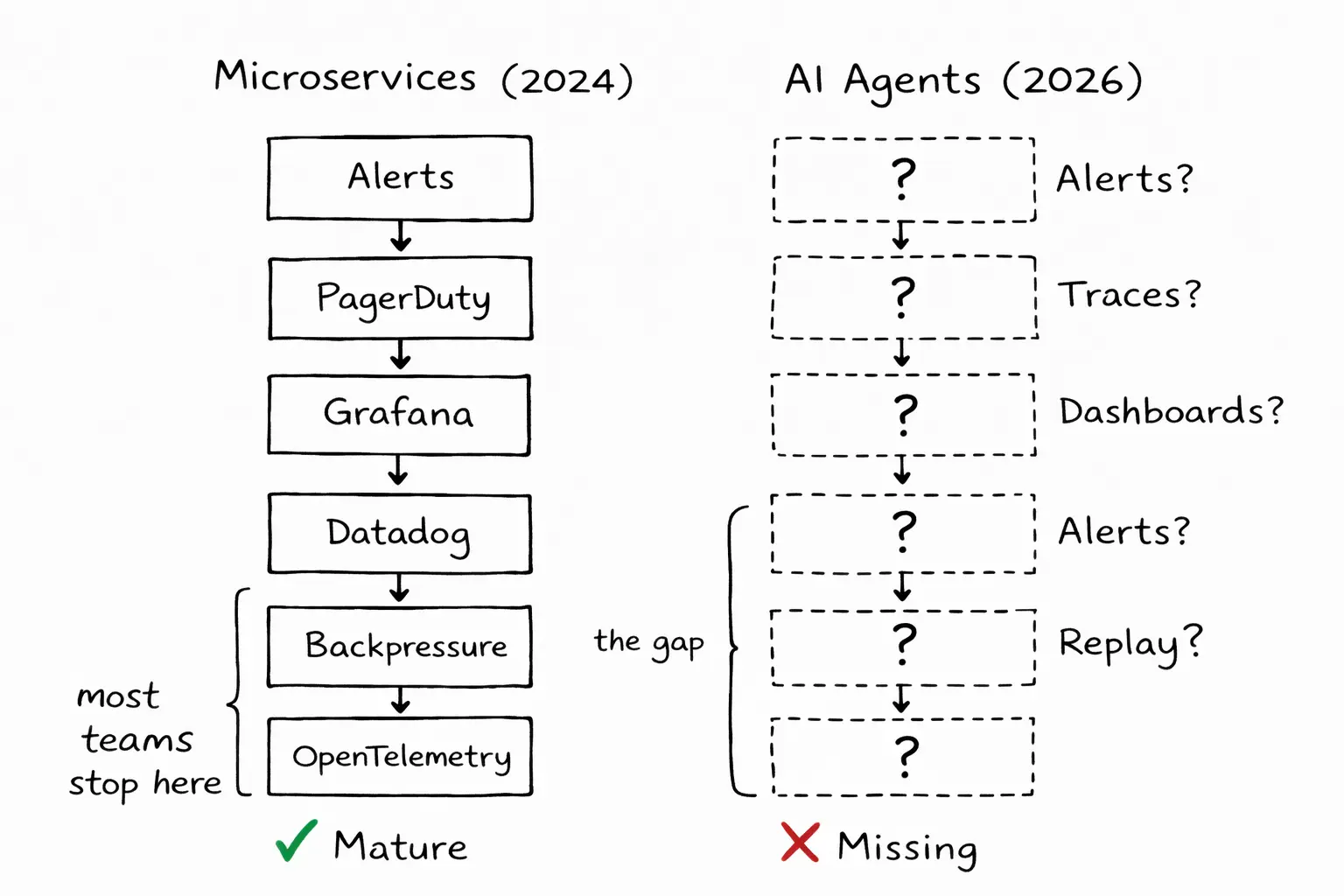
We have better observability for a Node.js microservice written by an intern than for an autonomous agent that just rewrote half a codebase.
We solved this problem before
In 2015, if a microservice failed in production, you would SSH into the server and grep through log files. Painful, slow, unreliable. The industry spent the next decade building a stack to fix it: OpenTelemetry for instrumentation, Datadog and Honeycomb for traces, Grafana for dashboards, PagerDuty for alerts.
Today, when a request fails across twelve services, you can trace it end to end. You can see where it broke, how long each hop took, what the payload looked like, and what error came back. You can replay the request. You can set alerts for similar failures.
AI agents are distributed systems. A single session involves multiple LLM calls, tool invocations, file reads and writes, command execution, and decision points where the model chose one path over another. The execution is non-deterministic. The failure modes are subtle, and the blast radius can be large.
There is no observability tooling.
What is missing
When an agent fails, or worse, succeeds at the wrong thing, you need to answer four questions.
1. What did it do?
Not what did it output. What did it do? Which files did it read? Which did it modify? What commands did it run? What API calls did it make? In what order?
Today, the answer lives in terminal scrollback. If you are lucky, the agent printed its actions. If you use Claude Code, you get a stream of tool calls mixed with conversation. If you use a background agent, you might get a log file. Unstructured. Verbose. Impossible to query.
There is no structured trace. No way to say "show me every file this agent touched in the last session" without parsing raw output.
2. Why did it do it?
The agent read a file, decided to refactor it, and introduced a bug. Why did it decide to refactor? What in the context led to that choice? Was it following an instruction from the system prompt? Responding to a pattern it saw in the code? Hallucinating a requirement?
In a microservice, you can trace a decision to a specific code path. In an agent, the "code path" is the model's attention over the context window. Opaque by design. But you can still capture the inputs to each decision: what was in the context when the model generated that tool call? What was the prompt? What tools were available?
Nobody captures this. The LLM request and response are ephemeral. When the session ends, the reasoning is gone.
3. What did it cost?
Token usage per session is available from most providers. But token usage per task? Per file? Per iteration? That granularity does not exist.
When an agent spends 45 minutes on a task and burns $12 in API calls, you cannot tell whether $10 was productive work and $2 was a retry loop, or whether $11 was the agent spinning in circles and $1 was the actual fix. Cost attribution at the task level is missing.
4. What was it allowed to do?
When an agent accesses a file, was it authorized to? When it ran a shell command, was that command within its permitted scope? When it called an external API, was that API on the allowlist?
Most agent frameworks do not log permission checks. The agent has access to everything, or it is blocked by a blanket prompt. There is no middle ground and no audit trail.
Why this matters now
Three things are converging.
Background execution is the default. Claude Code's headless mode, Codex's async tasks, Cursor's background agents, Ona's agentic environments and background agents. When the human is not watching, terminal scrollback is not observability. You need structured, queryable, persistent logs.
Autonomy is increasing. The path from "autocomplete" to "implement this feature" to "maintain this service" means agents make more decisions with less oversight. Each decision is a potential failure point.
Compliance will force the issue. The EU AI Act requires audit trails for high-risk AI systems. SOC 2 auditors are asking about AI agent governance. Enterprise customers want to know what the agent did and whether you can prove it. If you cannot answer with structured data, you cannot sell to enterprises.
What the stack should look like
The patterns exist in distributed systems observability. They need to be adapted, not invented.
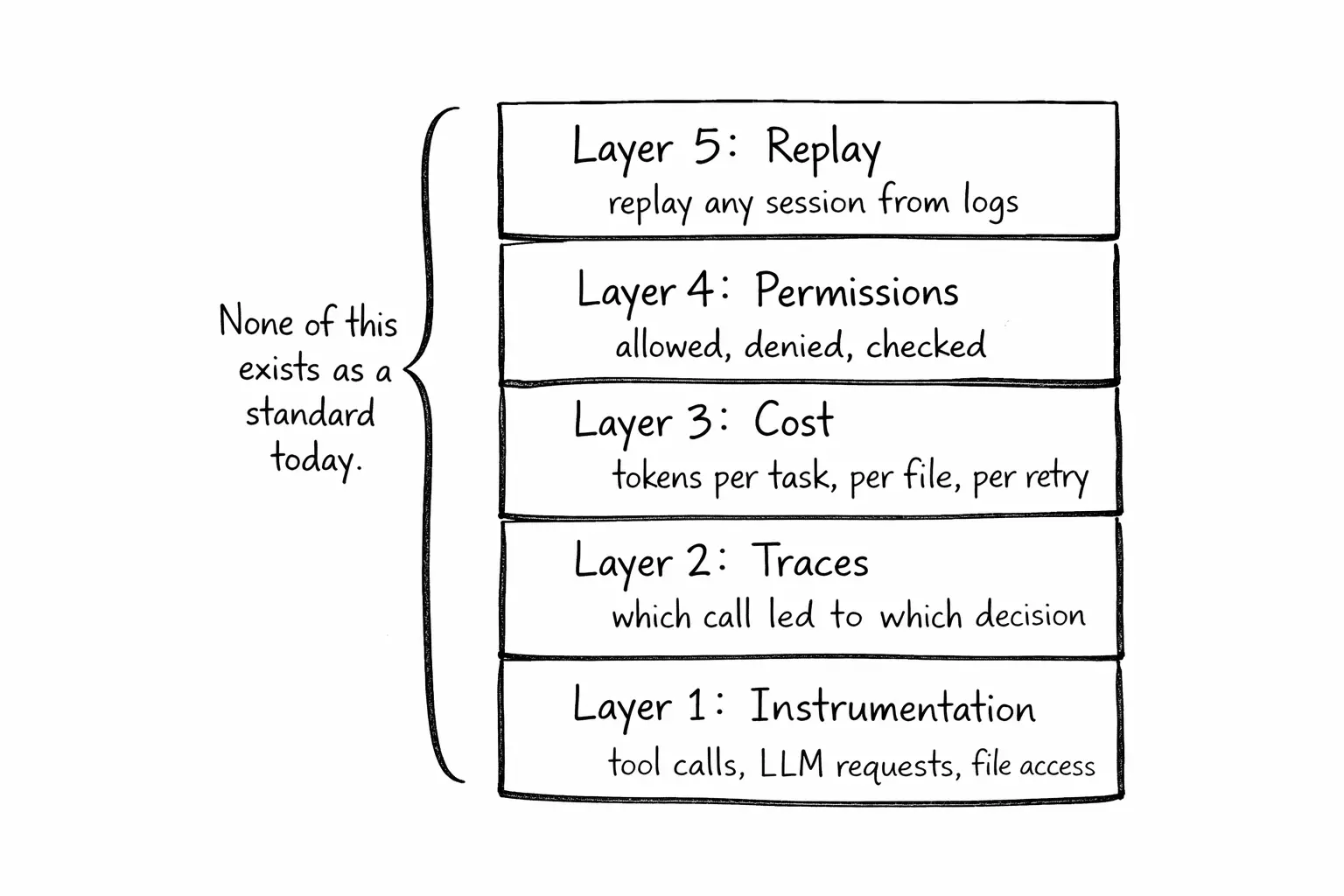
Structured event logging. Every tool call, LLM request, and file access gets a structured log entry: timestamp, inputs, outputs, duration, result. JSON lines. Queryable with standard tools. No proprietary formats. I built agent-trace to test this idea. It sits between the agent and its tools, captures every call, and writes NDJSON traces you can replay later. Zero dependencies. Works with Claude Code, Cursor, and any MCP client.
Causal traces. The agent read a file, which led it to modify another file, which caused a test to fail, which triggered a retry. These chains need to be captured as traces. A trace ID per task. Span IDs per tool call. Parent-child relationships between spans. This is OpenTelemetry's data model, applied to agent execution.
Cost attribution. Token usage tagged by task, by file, by iteration. When a task costs $8, you should be able to see: $2 for reading files, $1 for planning, $3 for writing code, $2 for retry loops. Go deeper and you can profile at the GPU level: which kernel operations are bottlenecks, where inference stalls, what the token-level latency looks like. I built LLMTraceFX for this. "AI is expensive" becomes something you can act on.
Permission audit trail. Every authorization check logged: what was requested, what policy applied, what the result was. Denials and grants both recorded.
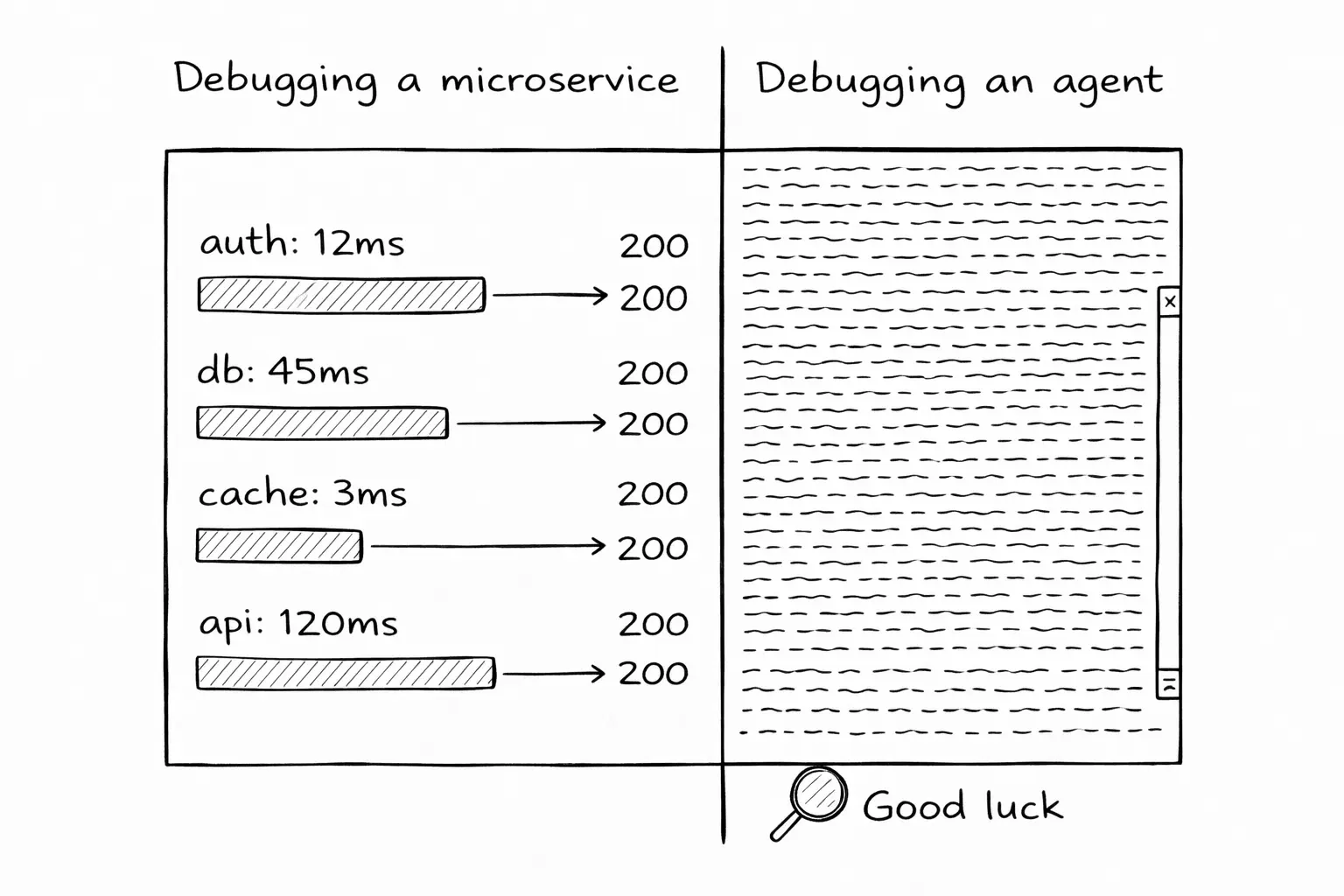
The gap is closing
Teams running agents in production are building ad-hoc logging. Enterprises evaluating agent adoption are asking about audit trails. Compliance frameworks will require structured records of what autonomous systems did and why.
The pieces are available. OpenTelemetry provides the instrumentation model. JSON lines provide the storage format. Existing tools can render the data. What is missing is the layer that instruments agent runtimes and produces structured, queryable, replayable traces.
I started over that day because I had no way to trace what the agent did. That should not be the normal debugging experience. We solved this for microservices. We can solve it for agents.
Update: This post sparked a good discussion on X. Several people shared similar frustrations. The common thread: everyone is building ad-hoc logging, nobody has a standard. That conversation pushed me to build agent-trace, an open-source tool that captures and replays agent sessions. It is a start, not a solution. The real answer will come from the community converging on shared formats and instrumentation.
The full treatment of this topic is in Chapter 14 of the Agentic Engineering Guide. If your team is working on agent observability, let's talk.