Let's suppose someone from your team have an idea. A good one. "What if we charged $20/month for this?" The idea gets written down, discussed, prioritized. Then it gets handed to engineering, who spend the next six weeks wiring up a payment gateway, building a landing page, setting up ad campaigns, and instrumenting analytics. By the time the data comes in, the team has moved on.
IMO, it is not a people problem. It's an infrastructure problem.
I know because I built the infrastructure to fix it. I would like to share some learnings & insights!

The thing nobody tells you about experimentation
Every company says they want to move fast and test ideas. Almost none have the infrastructure to do it. What they have is a process: write a spec, get it prioritized, assign it to a sprint, build it, ship it, measure it. Six weeks minimum. Sometimes twelve.
The companies that run fifty experiments a year instead of five don't have better ideas. They have shared infrastructure that makes each experiment cheap. When the cost drops from six weeks to six hours, you run more experiments. You find more things that work. It's just math.
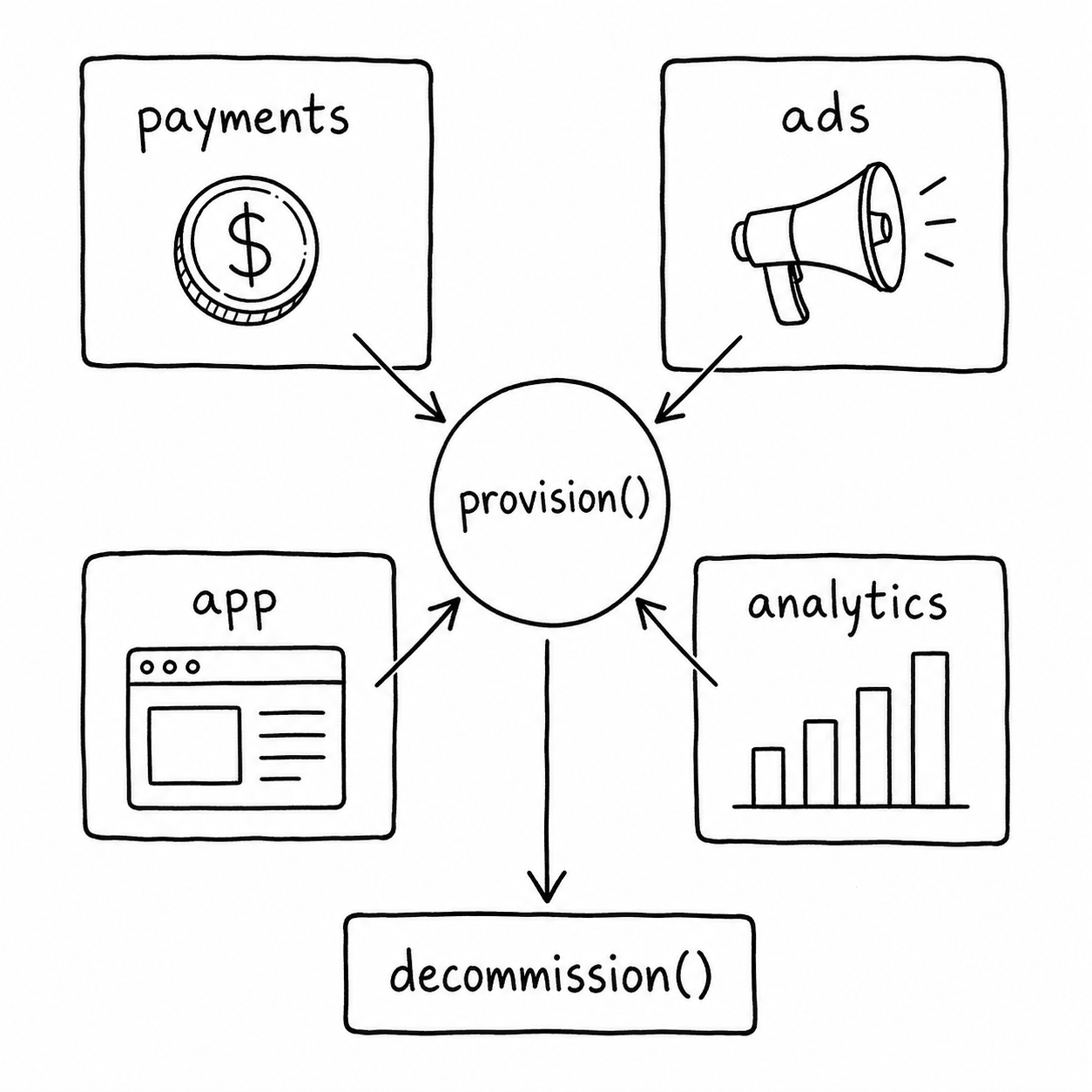
It's four modules and a decommission contract
Building an experimentation platform is not complicated. Spin up payment infrastructure, launch ad campaigns, deploy a landing page, instrument analytics, collect signals, make kill decisions. It looks like a lot. It isn't.
It's four modules, a registry, and a decommission contract. The rest is elbow grease.
The four modules:
payments a way to charge users (or capture leads)
ads a way to reach them
app a place to land
analytics a way to measure what happened
Each module has two operations:
provision(experiment_id, config) spins up the capability
decommission(experiment_id) tears it down cleanly
A product person fills in a config form: name, thesis, target audience, daily ad budget, price point, kill deadline. The platform calls provision() on all four modules in parallel. In under an hour, the experiment is live. When it's killed, decommission() runs in sequence.
What to build and what to buy
Most teams get this wrong in one of two directions.
Teams that build too much spend six months on a stats engine. They read about how Netflix built their experimentation platform and decide they need something similar. They don't. Netflix built their stats engine because PostHog didn't exist. Statsig estimates a minimum viable stats engine takes one year and five engineers. PostHog gives you 80% of that for free. Don't build the stats engine.
Teams that buy too much stitch together five SaaS tools and end up with a system nobody owns. No off-the-shelf product provisions a Stripe payment link, a Google Ads campaign, a Vercel or Netlify deployment, and a PostHog project in parallel, then tears all four down cleanly when the experiment is killed. That glue is what you build.
| What to build | What to buy |
|---|---|
| Experiment registry (Postgres) | Payments (Stripe) |
| Decommission contract | Ad campaigns (Pipeboard MCP) |
| Kill criteria engine | Ad copy (Claude Haiku or Sonnet) |
| Authorization layer (OpenFGA) | Landing page hosting (Vercel / Netlify) |
| Config form and dashboard | Analytics (PostHog) |
The things you build are the glue. The things you buy are the commodity. The glue is about 2,000 lines of TypeScript. The commodity is someone else's problem.
The payments module
Use Stripe. The API is clean, the metadata model is flexible, and subscription lifecycle management is mature. provision() creates a product, a price, and a payment link. decommission() cancels the link and any active subscriptions with cancel_at_period_end: true so users finish their billing cycle without a surprise charge.
For B2B experiments where the goal is a qualified lead, replace the payments module with a CRM webhook. HubSpot or Salesforce fires when a lead hits a qualification threshold. The module interface stays the same. provision() sets up the form and CRM integration. decommission() closes the form and archives the leads.
Tag everything with experiment_id in the metadata at creation time.
await stripe.products.create({
name: config.product_name,
metadata: {
experiment_id: config.experiment_id,
decommission_at: config.kill_at,
}
})
The decommission engine queries by metadata.experiment_id. Not a separate list. Not a database join. Stripe is the source of truth. Even if your registry goes down, you can find and cancel every payment object tied to an experiment.
If you're building for India: UPI is 60% of Indian digital payments. Swap Stripe for Razorpay and also Stripe has lot of invite-only things for India. The interface is identical. provision() creates a Razorpay plan and payment link with notes.experiment_id as the metadata tag. Everything else stays the same.
The ads module
In 2026, Google and Meta both have MCP servers (but they are very limited at the moment). Pipeboard ships a unified MCP with almost of Google Ads tools and Meta tools under a single auth. Full CRUD. Building raw API wrappers from scratch is four to six weeks of work Pipeboard has already done. Don't do it.
Ad creative generation costs almost nothing:
- Copy: Claude Haiku at $1/MTok input. Three headline variants costs $0.002.
- Voiceover: ElevenLabs Starter at $5/month. A 30-second clip costs $0.05.
- Images: Flux 1.1 Pro at $0.05/image. A ten-variant test set costs $0.50.
Total creative cost per experiment: under $1. The ad spend is the real cost, and that's the experiment budget, not platform overhead.
For B2C: Google Search and Meta. Broad targeting by city, age, interest. Copy is short and direct. For B2B: LinkedIn is the primary channel. Job title targeting, company size, industry. Copy leads with the problem, not the product. The ads.provision() config takes a channels parameter: ['google', 'meta'] for B2C, ['linkedin', 'google'] for B2B.
One constraint: use a single master ad account for all experiments, with campaign-level isolation via naming (EXP-{experiment_id}). Multiple ad accounts for the same business triggers Meta and Google policy flags.
The app module
Use Vercel or Netlify. Both have programmatic deployment APIs and wildcard subdomain support. On Next.js, Vercel is first-class. On anything else, Netlify's domain management API is slightly simpler & better.
Set up a wildcard subdomain once (*.experiments.yourdomain.com) and every new experiment gets its own subdomain with SSL auto-issued. No per-experiment DNS work.
With Vercel:
await vercel.deployments.createDeployment({
project: 'experiments-platform',
gitSource: { rootDirectory: `templates/${config.template}` },
env: [
{ key: 'HEADLINE', value: config.content.headline },
{ key: 'PAYMENT_LINK', value: config.content.payment_link },
{ key: 'NEXT_PUBLIC_POSTHOG_KEY', value: config.posthog_project_key },
]
})
With Netlify, the same pattern works via the Netlify API: create a site, deploy from a directory, set environment variables, attach the subdomain. Decommission calls deleteDeployment and redirects the subdomain to an archive page.
Build four templates once. Each reads content from environment variables injected at deploy time. No custom code per experiment.
B2C template: hero, pricing, CTA, social proof. B2B template: problem statement, solution overview, demo request form with Calendly embed. The form fires a webhook to your CRM on submission.
The analytics module
PostHog bundles analytics, feature flags, and session replay in one SDK. Each experiment gets its own scoped project key. Events from one experiment never mix with another.
The templates ship with PostHog auto-instrumentation. Page views, clicks, and form submissions are captured without custom event code. The funnel is configured at provision time.
B2C funnel: landing_view -> signup -> payment_initiated -> payment_complete
B2B funnel: landing_view -> scroll_depth_50 -> form_view -> form_submit -> demo_booked -> qualified_lead
The free tier covers 1M events per month. Ten parallel experiments at 50K events each is 500K. Well within free tier.
The kill criteria engine
Most teams skip this. It's the part that makes the platform worth building.
Without it, experiments die by neglect. Someone forgets to check the dashboard. The ad campaign runs for three weeks at 0.1% CTR. $700 in ad spend, zero signal. This happens constantly.
The engine pulls signals from three sources every six hours: ad platforms (impressions, clicks), payment provider or CRM (conversions, revenue), and PostHog (page views, signups, form submissions). It evaluates thresholds and kills automatically.
For B2C:
| Day | Condition | Action |
|---|---|---|
| 3 | Impressions > 1,000 and clicks = 0 | Kill. No signal. |
| 7 | CTR < 0.5% | Kill. Creative isn't working. |
| 14 | Payment conversion < 2% | Kill. Users aren't paying. |
| 14 | Payment conversion >= 2% | Flag for founder review. |
For B2B:
| Day | Condition | Action |
|---|---|---|
| 5 | Impressions > 500 and clicks = 0 | Kill. No signal. |
| 10 | CTR < 0.3% | Kill. LinkedIn CPCs are high. |
| 21 | Demo request rate < 1% | Kill. |
| 21 | Demo request rate >= 1% | Flag for review. |
B2B gets more time. LinkedIn CPCs are higher, so signal comes from fewer impressions. Sales cycles are longer, so the experiment needs more runway.
The kill is automatic. No one has to remember to check.
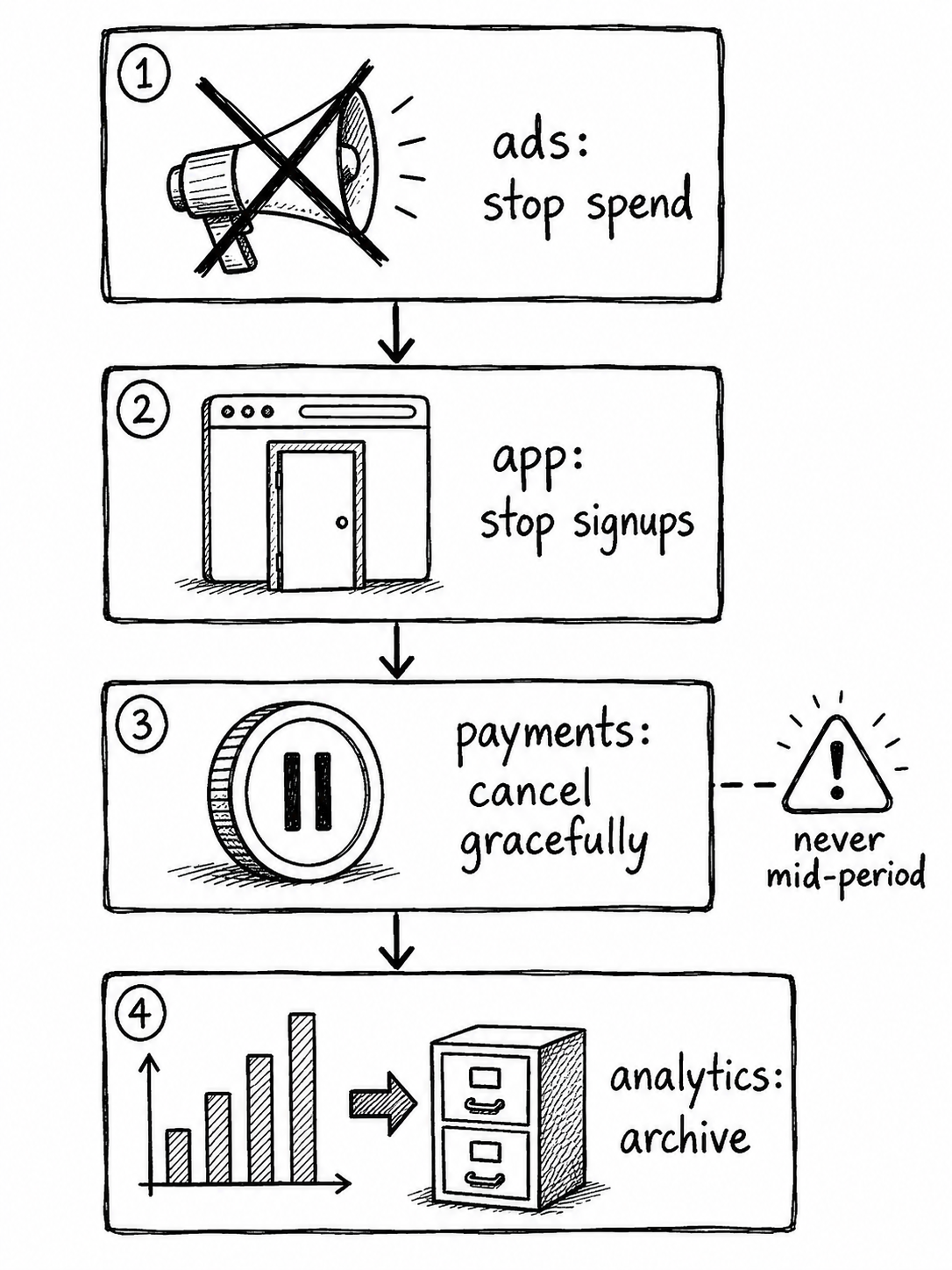
The decommission contract
This is the part most people get wrong.
Order matters:
1. ads.decommission() stop new spend
2. app.decommission() stop new signups
3. payments.decommission() stop new charges, cancel subscriptions gracefully
4. analytics.decommission() export data to S3, archive project
Stop traffic before stopping payments. Never leave a live landing page pointing at a dead payment link. Never cancel subscriptions mid-period. Use cancel_at_period_end: true. Never delete anything. Archive everything.
Four rules every module must follow:
- Idempotent. Calling
decommission()twice has the same result as once. - Non-destructive. Nothing is deleted. You will want this data later.
- Ordered. Stop traffic before stopping payments.
- Async-safe. Decommission can be called while a payment is in-flight.
If you build nothing else from this post, build the decommission contract. Without it, you're just provisioning things and hoping someone remembers to clean them up.
The authorization layer
At ten parallel experiments, questions come up fast. Who can kill which experiment? Can a PM decommission something they didn't create? Can the kill engine act without human approval?
OpenFGA handles this. It's Google Zanzibar-style authorization, the same model that powers Google Drive's sharing. I'm a maintainer of the project.
type experiment
relations
define creator: [user]
define org_admin: [user]
define can_kill: creator or org_admin
define can_auto_kill: [system]
The kill engine checks can_auto_kill before acting. A PM checks can_kill. The founder has org_admin and can override anything.
The same model works for AI agents acting on behalf of users. When your agent sends a message or books a call for a user, who authorized that? What can it do? Build the authorization layer once. Use it everywhere.
The orchestration layer
Two tools, two jobs.
Trigger.dev defines the workflow logic. It's Postgres-backed, open source, self-hostable. The durable timer primitive handles the kill-criteria schedule cleanly:
await killCriteriaCheck.trigger(
{ experiment_id: payload.experiment_id },
{ delay: '3d' }
)
That delay: '3d' pauses the workflow, frees the worker, and resumes at day 3. No cron jobs. No polling. No missed checks. Not Temporal because Temporal requires a separate server and a Database. Right answer at Uber scale. Overkill for ten experiments a month.
Ona runs the agents that execute the work. Ona is a platform for background agents: task in, pull request out, running in full cloud environments with your tools, network access, and scoped credentials. The kill criteria engine, the signal collector, the provision and decommission workflows are all background agent workloads. Ona runs them in isolated environments with audit trails and kernel-level policy enforcement.
What it actually costs
Platform overhead per experiment, excluding ad spend:
| Component | Cost |
|---|---|
| Stripe | $0 fixed (% per transaction only) |
| Vercel Pro | $0 per experiment ($20/month flat) |
| PostHog | $0 (free tier: 1M events/month) |
| Trigger.dev | $0 (free tier: 50K runs/month) |
| Claude Haiku (copy) | ~$0.002 |
| ElevenLabs (voiceover) | ~$0.05 |
| Flux images | ~$0.50 |
| Pipeboard MCP | ~$5 (shared across all experiments) |
| Total | ~$6 per experiment |
Against six weeks of engineering time per experiment, the platform pays for itself after five experiments.
Build time: six weeks solo for the MVP. Payments, ads, app scaffold, kill criteria engine, authorization, dashboard. Phase two adds the analytics module, LinkedIn Ads, and voiceover pipeline in three to four more weeks.
What big tech learned
Netflix, Uber, and Airbnb all built their experimentation platforms from scratch. Uber's experiment evaluation engine took years to mature. Zalando went through three phases over six years. Eppo was founded by an ex-Airbnb data scientist because building this in-house is painful.
They built everything from scratch because the commodity tools didn't exist. PostHog didn't exist. Stripe didn't exist. Vercel didn't exist. They had no choice.
You do. Buy the stats layer. Buy the payment layer. Buy the deployment layer. Build the provisioning and decommission glue. That's the IP.
The three things worth building: the decommission contract, the kill criteria engine, and the experiment registry. Everything else is bought.
The thing to take away
The bottleneck at most product companies isn't ideas. It's the cost of testing them.
The platform doesn't make you smarter. It makes being wrong cheaper.
I'm a software engineer at Ona (OpenAI to acquire Ona), where I've spent four years building the platform infrastructure that 1.7M developers use to write code. Outside of that, I maintain agent-trace (observability for AI agents), agentic-authz (authorization patterns for agents), and Distill (token reduction for LLM context). I'm also a core maintainer of OpenFGA. The experimentation platform described in this post draws directly on that work. If your company is trying to move faster on product experiments and the bottleneck is infrastructure, I can help you build this. Reach me at hi@siddhantkhare.com or schedule a call.