A few weeks ago I wrote about AI fatigue. Hundreds of engineers reached out - in comments, DMs, emails - and a pattern emerged that I didn't expect.
The fatigue isn't random. It has a specific cause. And it has a specific fix.
You were never supposed to be the quality gate

Here's what I kept hearing, in different words, from different people:
"I spend more time reviewing AI output than I used to spend writing the code myself."
"The AI generates code fast, but I still have to check every line. It's like having an intern who types at 10,000 words per minute."
"My PR queue went from 25 a week to over 100. The code is AI-generated. The review is still me."
I lived this. As an open source maintainer, I went from 20-25 pull requests per week to over 100. Most of them AI-generated. Lengthy machine-written descriptions. Seven or eight sloppy PRs for the same issue. Each one requiring the same careful review as a human-written PR - actually more careful, because AI-generated code looks confident even when it's wrong.
I talked to an engineering lead at a mid-size SaaS company. One of their engineers reviewed over a hundred pull requests in two weeks. About 20 file changes each. A significant chunk of the AI-generated code required manual fixes. That's one person, acting as the quality gate for an entire team's AI output.
I've talked to engineering leaders at companies ranging from 50-person startups to teams with over a thousand engineers. The story is the same everywhere. They've been using Copilot, Cursor, and Claude Code for months. More PRs are being generated. But merge times haven't changed. The bottleneck didn't disappear. It moved. From production to review.
This is the pattern: AI made code generation fast. It didn't make code verification fast. So the human became the bottleneck.
The data confirms it:
- DX's latest research across 121,000 developers at 450+ companies: 93% use AI assistants, but productivity gains plateaued at 10% and haven't budged.
- A METR study found experienced open-source developers were 19% slower with AI coding tools - despite believing they were 24% faster.
More code is being produced. The same amount of human attention is required to verify it. And being the bottleneck all day, every day, is what creates the fatigue.

The concept that explains all of this
There's an engineering concept that explains exactly what's happening and exactly how to fix it. It comes from systems engineering, and it's called backpressure.
In distributed systems, backpressure is the mechanism that prevents a fast producer from overwhelming a slow consumer. A few people in the agent engineering space have started applying the concept - BoundaryML calls it "agentic backpressure," the Ralph Wiggum loop community builds entire workflows around it - but it hasn't made it into the mainstream conversation yet. If a message queue produces events faster than the downstream service can process them, backpressure slows the producer down or buffers the excess. Without it, the system crashes.
The same principle applies to AI agents. The AI is the fast producer. You are the slow consumer. And right now, most teams have zero backpressure between the two.
When an AI agent generates code, what checks its work before it reaches you?
If the answer is "nothing" - if the code goes straight from the model to a pull request, and you're the first line of defense - then you are the backpressure. Your brain is the buffer. Your review capacity is the rate limiter. And unlike a message queue, your brain doesn't scale horizontally.
This is why you're tired. The system around the AI has no automated feedback loop. Every mistake, every hallucination, every subtle bug flows directly to you for judgment. And judgment is the most expensive cognitive operation a human performs.
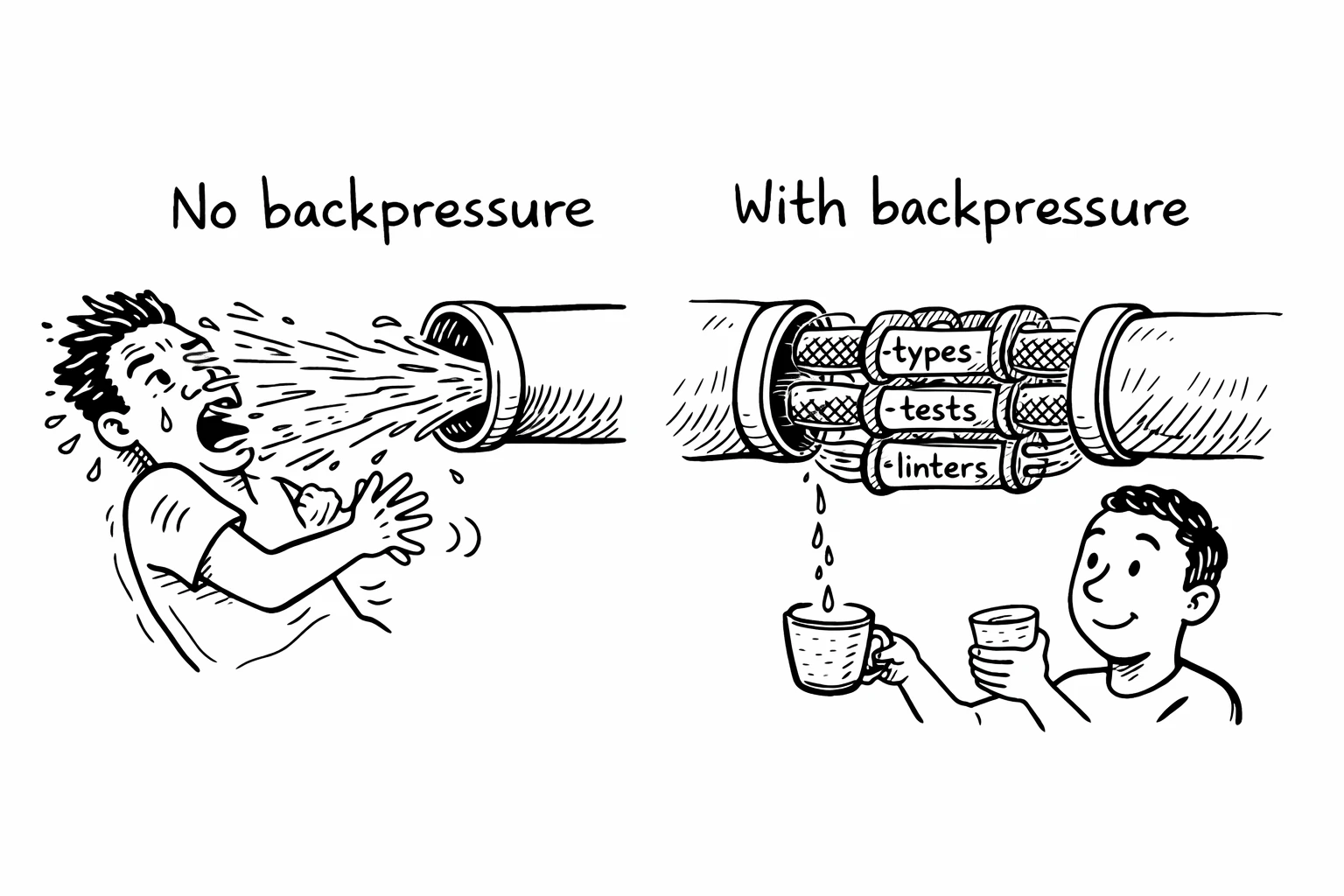
What backpressure actually looks like
Backpressure for AI agents means automated feedback mechanisms that catch mistakes before they reach a human. The agent makes an error, the system tells it, and the agent corrects itself - without you being involved.
This isn't theoretical. The teams I've talked to that are successfully adopting AI at scale all have one thing in common: they invested in automated feedback before they invested in AI tooling.
Here's the hierarchy, from strongest to weakest:
Type systems
A strong type system is the most effective form of backpressure. When an AI agent generates code in TypeScript with strict mode, Rust, or Go, the compiler catches entire categories of errors instantly. Wrong types, missing fields, impossible states - the agent gets immediate feedback and can self-correct.
Languages with expressive type systems have been growing in popularity partly because of this. It's not just that typed languages produce better code. It's that they produce better feedback - and that feedback is what keeps agents on track.
The quality of error messages matters too. Rust's compiler doesn't just say "type error." It explains what went wrong, suggests a fix, and points to the exact location. That explanation feeds directly back into the LLM. The better the error message, the more likely the agent self-corrects on the first try.
If you're choosing a language for a new project that will involve heavy AI-assisted development, the strength of the type system should be a primary factor. The agent needs types to catch its own mistakes.
Test suites
A failing test is a signal. It tells the agent: "what you just did broke something." A passing test tells the agent: "you're on the right track."
The teams that get the most out of AI agents are the ones with fast test suites. The role of tests has changed. Tests used to be a safety net for humans. Now they're a feedback loop for machines.
The key word is fast. If your test suite takes 20 minutes to run, the agent sits idle for 20 minutes between attempts. That's 20 minutes where it could be iterating. The faster the feedback loop, the more iterations the agent can make, and the better the final output.
I've seen teams cut their test suite runtime from 15 minutes to 90 seconds specifically to improve agent performance. The investment paid for itself in a week.
Linters and pre-commit hooks
Before AI, pre-commit hooks were annoying. They slowed down your commit flow. You'd disable them when you were in a hurry.
Now that agents are doing the committing, it doesn't matter if pre-commit hooks add 30 seconds. The agent doesn't care. It doesn't get frustrated. It doesn't disable them. And every issue caught by a linter is an issue that doesn't reach your review queue.
The pattern: anything that was "too annoying for humans" is now free for agents. Strict linting rules, formatting enforcement, import ordering, dead code detection. Turn it all on. The agent will comply without complaint, and your review burden drops.
Visual verification and architectural enforcement
For frontend work, tools like Playwright let agents see what they've rendered. The agent makes a CSS change, takes a screenshot, and compares it to the expected result. If the button is in the wrong place, the agent knows - without you having to look at it.
For backend work, tools like ArchUnit let you define architectural rules as code. "Services in the API layer cannot import from the database layer." When an AI agent violates these rules, the build fails with a clear message. One team I talked to references their ArchUnit rules directly in their AGENTS.md file - the instruction file that tells AI agents how to work in a codebase. The agent knows the boundaries before it starts.
Human review (last resort)
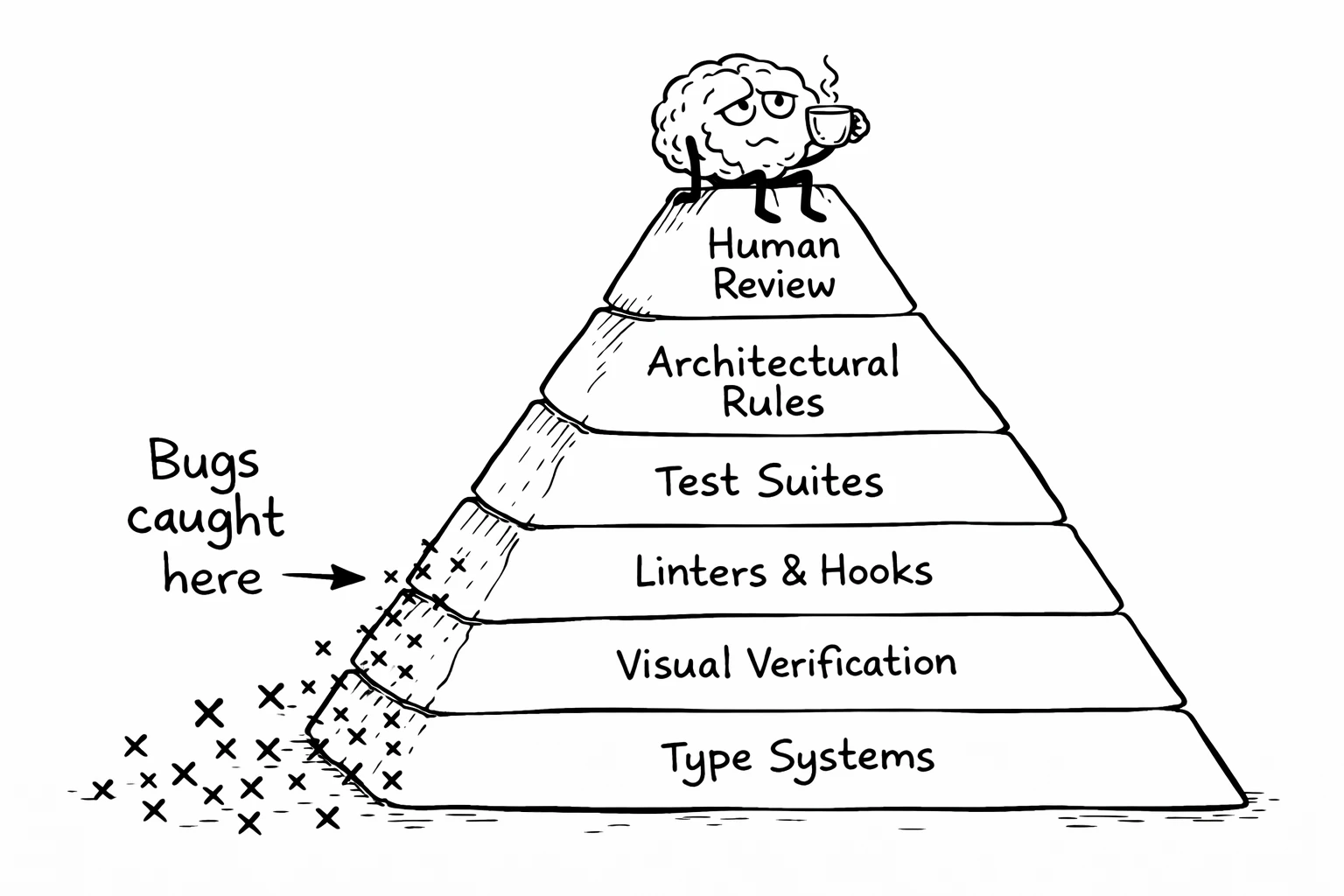
Notice where human review falls in this hierarchy. Last.
The goal isn't to eliminate human review. It's to make sure that by the time code reaches a human, the trivial issues are already resolved. The types check out. The tests pass. The linter is happy. The architecture is respected. The UI looks right.
What's left for the human? The things humans are actually good at: "Does this approach make sense for our system? Does this match our product requirements? Is this the right abstraction?" High-level judgment, not catching missing imports.
The SaaS team I mentioned earlier figured this out. They implemented a multi-layer review process: AI does a first pass and catches the majority of issues before a human ever sees the PR. The human reviewer spends their cognitive budget on the hard problems, not the obvious ones.
To be clear: backpressure doesn't catch everything. An agent can write code that passes every test, satisfies every linter, and respects every architectural boundary - and still be the wrong approach for the problem. Backpressure reduces the noise so you can focus on the signal. It doesn't replace your judgment. It protects it.
The tuning problem
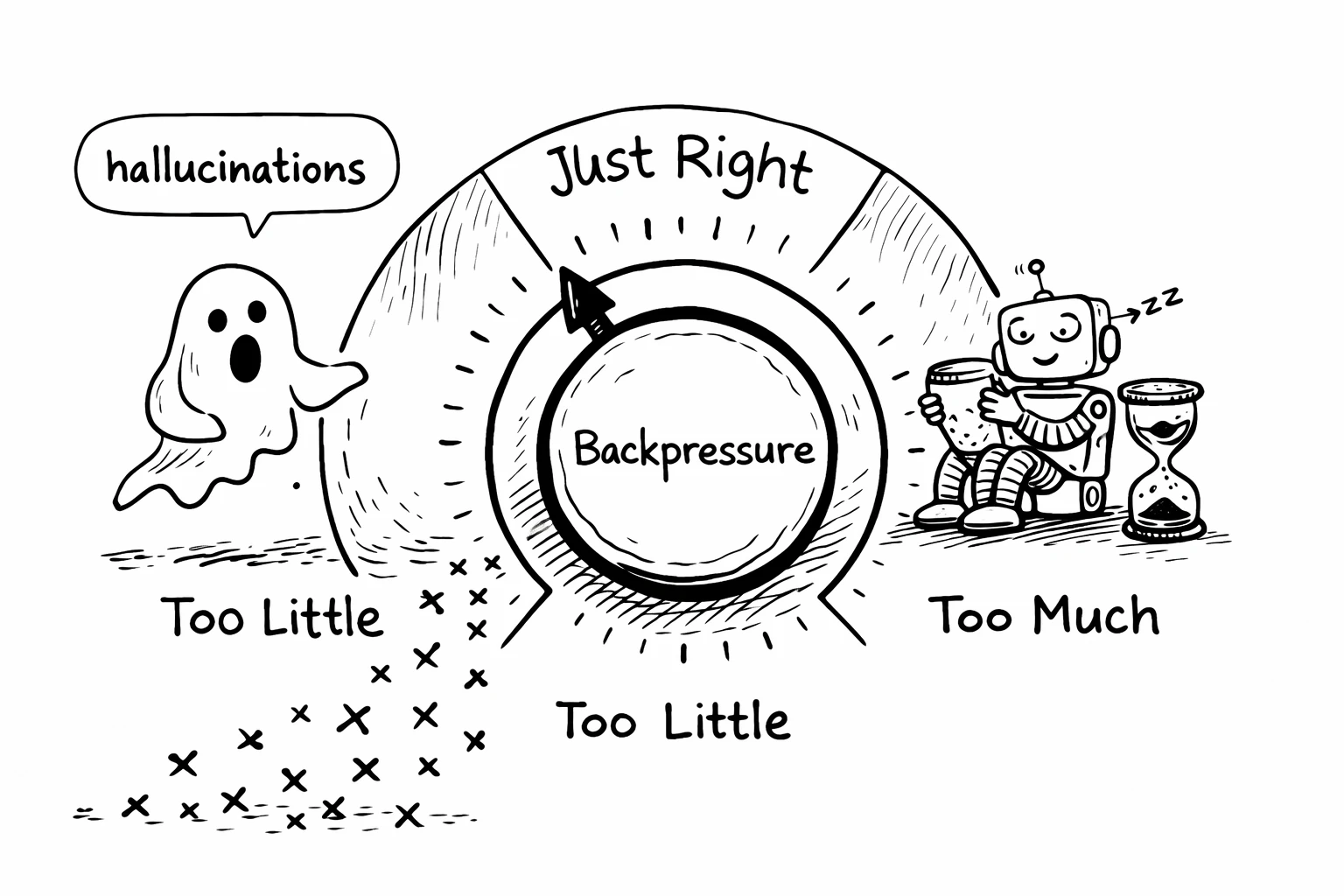
Backpressure isn't binary. It's a dial. And getting the setting right matters.
Too little backpressure: Hallucinations pass through. The agent generates code that compiles but is subtly wrong. It reaches your review queue looking clean, and you have to catch the logic errors yourself. This is where most teams are today.
Too much backpressure: The feedback loop is too slow. Tests take 20 minutes. The build takes 10 minutes. The agent spends more time waiting for feedback than iterating. You lose the speed advantage that made AI useful in the first place.
The sweet spot is fast feedback that catches real errors without creating a new bottleneck. This depends on your codebase, your test infrastructure, your deployment pipeline.
A practical heuristic: if your agent can complete a full iteration cycle (edit, build, test, feedback) in under 2 minutes, you're in a good range. If it takes more than 5 minutes, you're losing too much to wait time. If it takes under 30 seconds, check that your tests are actually catching real issues and not just rubber-stamping everything.
The connection to fatigue
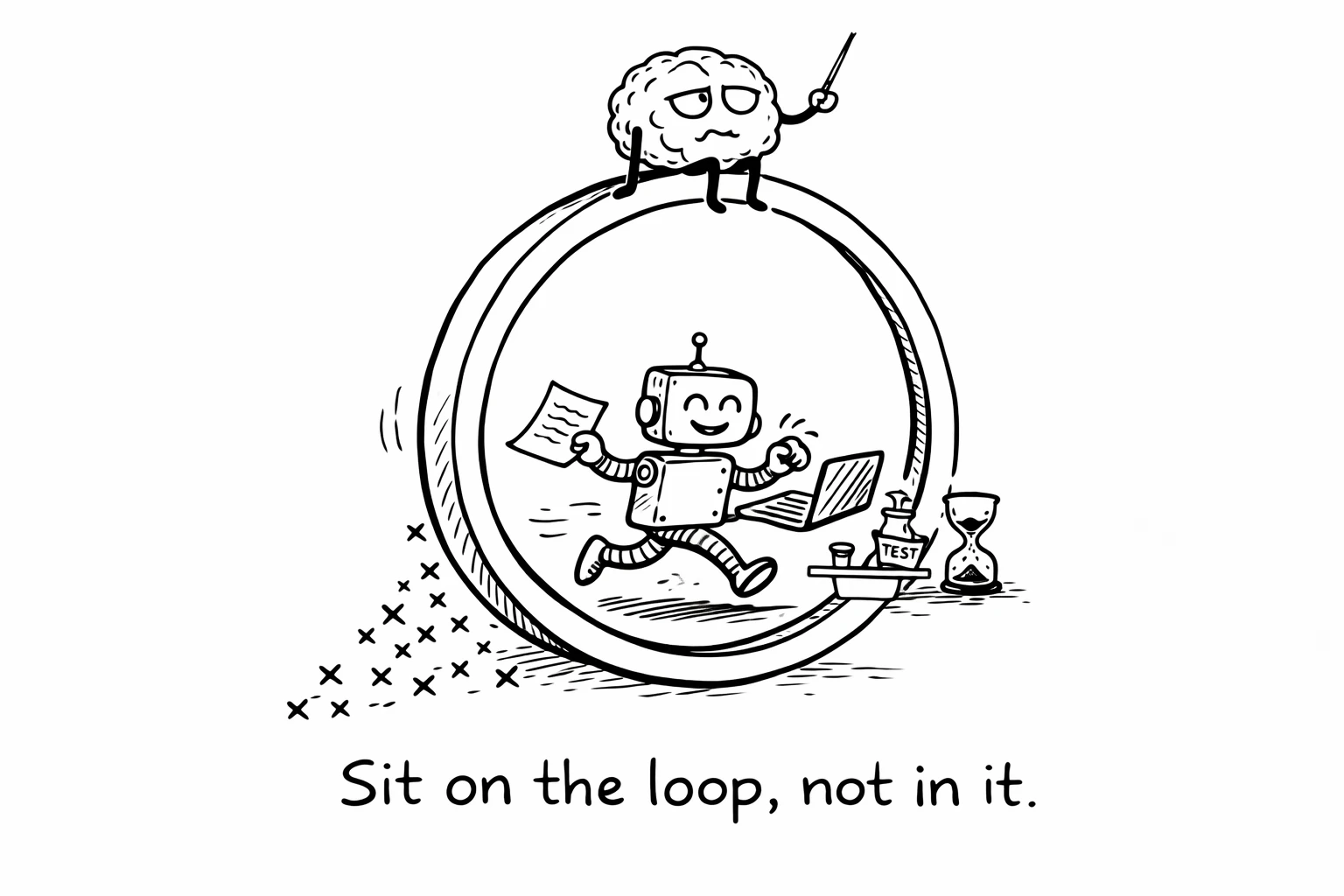
The hierarchy I described above covers code quality - types, tests, linters, architecture. But backpressure applies beyond code too. The context that goes into the model matters as much as the code that comes out. Distill is backpressure for context quality - it removes redundant information before it reaches the model, so the output is cleaner and requires less review. And what the agent is allowed to do matters as much as what it produces. Agentic-authz is backpressure for permissions - it constrains what agents can access, so you don't have to worry about whether the agent touched something it shouldn't have.
The engineers I've talked to who are thriving with AI aren't working harder than the ones who are burning out. They have better infrastructure. They invested in the feedback loop. They built the guardrails. And now they sit on top of the loop instead of inside it.
The fatigue is a signal. Your system is missing a layer. Not a better model. Not a better prompt. A better feedback loop.
What to do this week
If you're feeling the review burden, here's where to start:
Measure your iteration cycle time. Time the gap from "agent makes a change" to "agent gets feedback." If it's over 5 minutes, that's your first bottleneck. Speed up your tests before you do anything else.
Turn on everything you turned off. Strict linting, pre-commit hooks, formatting enforcement, import ordering. All the things that were "too annoying for humans." Agents don't get annoyed.
Check your type coverage. If you're in TypeScript, enable strict mode. If you're starting a new project, choose a language with strong types. Not for you - for the agent.
Encode your most common catch. Think about the mistake you keep finding in AI-generated PRs - the thing you catch every time. Now encode it as a rule. A linter rule, a pre-commit check, an ArchUnit constraint. Automate that one catch so you never have to make it again.
Move human review to last. If you're reviewing AI-generated PRs before any automated checks run, flip the order. Let CI catch the easy stuff first. Your eyes should be the last thing that touches the code, not the first.
Build the backpressure. The exhaustion will follow the bugs - out of your queue and into the machine's.
I'm building backpressure infrastructure for AI agents (Distill, agentic-authz) and I'm a core maintainer of OpenFGA (CNCF Incubating). If your team is figuring out how to adopt AI agents without burning out your engineers, I'd like to hear about it.